Modern enterprises operate in a state of constant data change. Customer information updates across CRM systems, product attributes evolve in commerce platforms, suppliers shift across procurement tools, and regulatory requirements continuously reshape governance expectations.
Traditional Master Data Management was designed for a slower world. Data was ingested periodically, models were carefully designed in advance, and golden records were recalculated in scheduled cycles.
That model is now breaking down.
AI, distributed cloud systems, and the rapid growth of operational data require a continuous approach to Master Data Management, where data is unified, corrected, and governed in real time rather than through periodic projects.
This shift has given rise to continuous Master Data Management with AI, often implemented through agentic data management platforms. In these systems, autonomous AI agents act as digital data stewards, continuously monitoring and improving master data while human experts maintain oversight and governance.
In this guide you will learn
- What continuous Master Data Management is and why enterprises are adopting it
- How agentic data management platforms use AI agents to manage data
- The difference between rule based and agent based governance
- A practical roadmap for implementing continuous MDM
- The role of human oversight in AI driven data governance
- How graph native architectures enable modern MDM
- Why agentic Master Data Management is becoming critical in Europe’s regulatory environment
Understanding Continuous Master Data Management
Continuous Master Data Management is an operational model where master data is continuously unified, improved, and governed using automation and AI driven workflows.
Rather than periodically rebuilding golden records through batch processes, continuous MDM maintains trusted records in place and in real time as new data arrives.
Definition
Continuous Master Data Management is an approach that leverages AI automation to synchronize, cleanse, and unify master data in real time, ensuring golden records always reflect the latest enterprise information.
This model enables:
- real time data quality monitoring
- continuous golden record management
- automated data onboarding and mapping
- proactive governance enforcement
The shift to continuous MDM addresses several structural weaknesses in traditional implementations.
Why Traditional MDM Struggles
Conventional MDM projects often face three systemic challenges:
Manual modelling overhead
Data models must be designed in advance before onboarding new systems.
Delayed updates
Golden records are recalculated periodically rather than continuously.
Data silos and duplication
Organizations replicate data across integration pipelines and warehouses.
In rapidly evolving digital environments, these limitations lead to outdated records, governance gaps, and costly operational friction.
Traditional MDM vs Continuous MDM
| Dimension |
Traditional MDM |
Continuous MDM |
| Update frequency |
Scheduled batch updates |
Real time event driven updates |
| Automation |
Manual rules and scripts |
AI driven automation |
| Data onboarding |
Manual mapping |
AI assisted schema discovery |
| Governance |
Periodic reviews |
Continuous policy enforcement |
| Human effort |
High operational overhead |
Human review only for exceptions |
| Golden records |
Periodically recalculated |
Continuously maintained |
Continuous MDM transforms master data from a periodic integration exercise into an always operating system for trusted enterprise data.
The Evolution of Master Data Management
The Agentic Master Data Management maturity model describes how organizations evolve from fragmented data systems to fully autonomous AI-driven data governance.
Early stages rely on manual data stewardship and rule-based processes. More advanced stages introduce AI-assisted automation and real-time synchronization. At the highest level of maturity, autonomous AI agents continuously manage and improve enterprise master data while humans provide governance oversight.
What Is Agentic Data Management?
Agentic data management is the architectural model that enables continuous master data management.
In this approach, autonomous AI agents operate across enterprise data systems to discover, unify, govern, and improve master data.
Definition
Agentic data management leverages autonomous AI agents to discover, unify, govern, and correct master data across systems while continuously learning from human feedback.
These AI agents function as digital data stewards, capable of performing tasks that traditionally required large teams of data engineers and governance specialists.
Typical agent capabilities include:
- automated schema mapping
- entity resolution and deduplication
- data quality profiling
- policy enforcement
- anomaly detection
- metadata generation
Importantly, these agents operate within governance guardrails, meaning they can automate routine work while escalating ambiguous or high risk decisions to human experts.
This model creates a hybrid governance approach, combining AI autonomy with human oversight.
Agent Based Governance vs Rule Based Systems
Traditional data governance relies heavily on static rules.
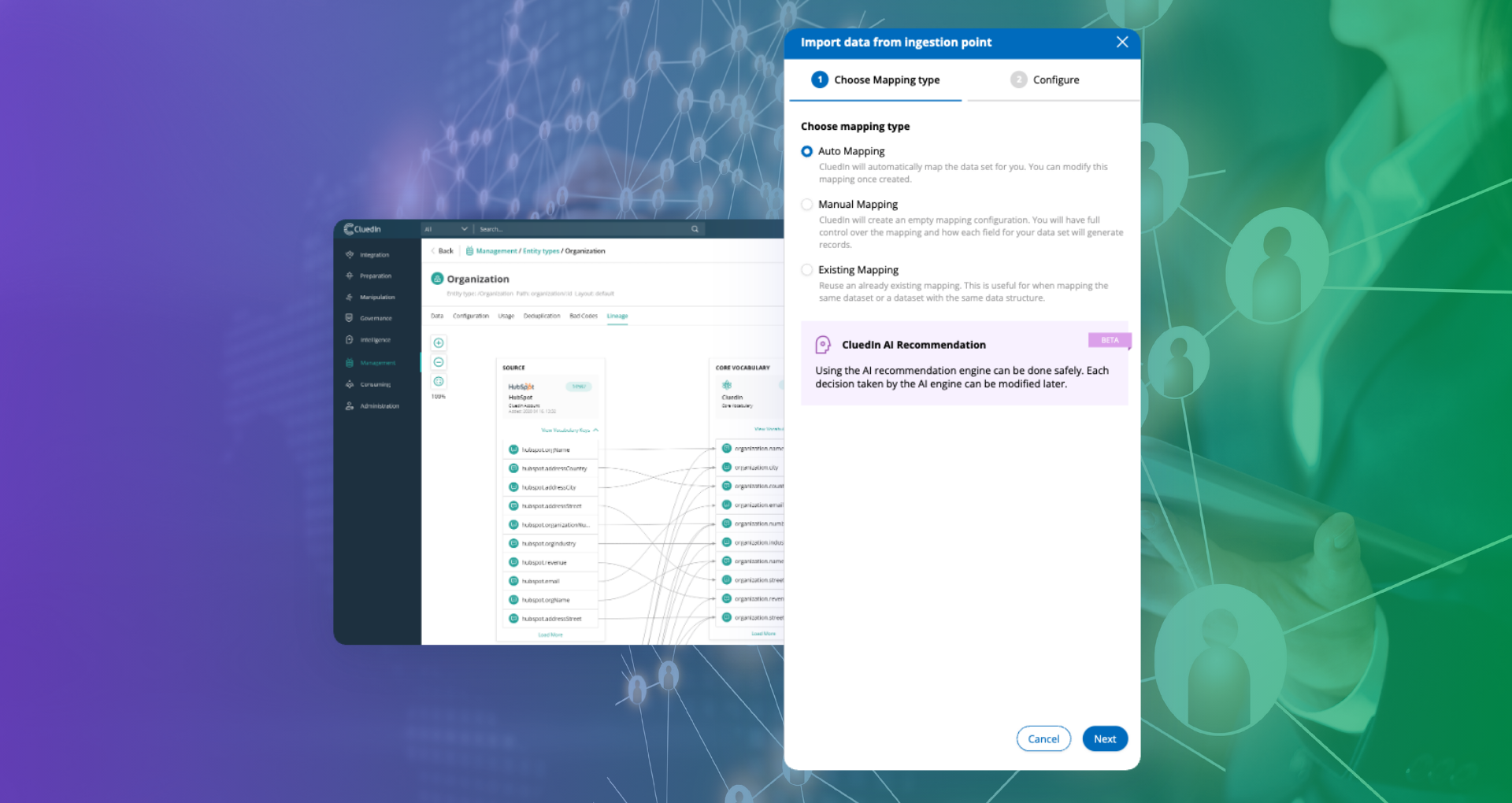
Image: Agent Based Governance vs Rule Based Systems
Rules specify exact conditions such as:
If field = null → reject record
If duplicate found → merge record
While effective for simple scenarios, rule based systems struggle with real world data complexity. Agent based governance introduces adaptive decision making.
Core Differences
| Capability |
Rule Based Governance |
Agent Based Governance |
| Decision logic |
Static predefined rules |
Context aware AI interpretation |
| Adaptability |
Requires manual rule updates |
Learns from feedback |
| Data quality remediation |
Manual intervention |
Automated remediation |
| Scalability |
Limited by human rule creation |
Scales with AI automation |
| Handling ambiguity |
Fails or escalates |
Uses probabilistic reasoning |
| Human role |
Operational execution |
Oversight and policy definition |
In practice, agentic governance systems can resolve issues such as fuzzy entity matches, schema inconsistencies, and conflicting records far more efficiently than rigid rule sets.
Human stewards remain involved for:
- regulatory sensitive decisions
- low confidence entity matches
- governance exceptions
This human in the loop model ensures trust while dramatically reducing operational workload.
How AI Agents Manage Master Data
AI agents orchestrate the full lifecycle of Master Data Management.
AI agents continuously improve master data while humans oversee exceptions.
Instead of executing a static pipeline, they operate as autonomous workflows continuously improving enterprise data.
Agent Driven MDM Workflow
1.
Automated Data Ingestion
Agents monitor new sources and automatically detect schema structures, metadata, and field patterns.
2.
Schema Mapping
Using natural language processing and pattern recognition, agents propose mappings between systems.
Example:
- Addr_Line_1 → Street Address
- Cust_ID → Customer Identifier
3.
Entity Resolution
Machine learning models identify duplicate or related records across systems.
These models evaluate:
- name similarity
- address patterns
- identifier matches
- behavioral signals
4.
Golden Record Creation
The platform merges resolved entities into a unified master record.
5.
Continuous Data Quality Monitoring
Agents monitor records for anomalies, inconsistencies, and missing values.
6.
Learning from Steward Feedback
Human approvals or rejections improve future decisions through reinforcement learning.
This creates a continuous improvement loop for data quality and governance.
Core AI Capabilities in Continuous MDM
AI introduces several capabilities that significantly change how master data platforms operate.
Automated Data Onboarding
AI models analyze source structures and automatically infer schema relationships.
Predictive Data Quality Monitoring
AI models continuously monitor for anomalies such as invalid addresses, inconsistent classifications, and suspicious record changes.
Automated Metadata Generation
AI can tag datasets with contextual metadata describing ownership, classification, lineage, and quality indicators.
This reduces the time required to onboard new systems from months to days. High performing systems can automate the majority of matching decisions.
Example results from industry deployments include automated match rates exceeding 97 percent, dramatically reducing manual stewardship effort.
Rather than reacting to errors, organizations can detect quality issues proactively. Improved metadata dramatically increases data discoverability and reuse.
Implementing Continuous Master Data Management
Adopting continuous MDM requires both technology and operational changes. Successful implementations typically follow a pilot first strategy.
Implementation Roadmap
| Phase |
Objective |
| Discovery |
Identify high value data domains |
| Data onboarding |
Connect and profile source systems |
| Schema mapping |
Establish cross system relationships |
| Entity resolution |
Configure deduplication models |
| Governance workflows |
Define stewardship policies |
| Monitoring |
Track quality metrics and agent performance |
| Domain expansion |
Extend across additional entities |
The most successful projects start with one high impact domain such as customer data or supplier records. This approach allows organizations to validate outcomes before scaling enterprise wide.
Defining Scope and Success Metrics
Clear measurement is essential to prove value. Typical success metrics include:
- data completeness
- duplicate reduction
- entity match rate
- time required to onboard new data sources
- steward review workload
- downstream business impact
For example, improvements in master data quality often lead to measurable outcomes such as:
- fewer order errors
- improved marketing segmentation
- faster compliance reporting
Automated Data Discovery and Schema Mapping
One of the most time consuming tasks in traditional MDM is mapping source schemas. AI dramatically accelerates this process.
Schema Mapping Definition
Schema mapping leverages AI models to identify relationships between fields across systems and propose mapping suggestions.
For example:
- Customer_Name → Client_Name
- Addr_Line_1 → Street_Address
- Prod_ID → SKU
Benefits include:
- faster onboarding of new systems
- reduced manual mapping effort
- lower integration errors
Entity Resolution and Data Quality Enforcement
Entity resolution is the core of Master Data Management. Machine learning models evaluate multiple signals to determine whether two records represent the same entity.
Signals can include:
- name similarity
- email address patterns
- phone numbers
- geographic proximity
- behavioral attributes
Continuous monitoring ensures duplicates and inconsistencies are corrected automatically or escalated to human stewards when confidence is low.
Establishing Governance and Stewardship Workflows
Automation does not eliminate governance. Instead, it shifts governance toward policy definition and oversight. Effective governance frameworks include:
- role based access control
- automated policy enforcement
- stewardship workflows for exception handling
- audit logging for compliance
This ensures that even as automation increases, accountability and transparency remain intact.
Continuous Monitoring and Model Retraining
Data environments evolve continuously. Therefore, MDM models must also evolve. Organizations should monitor:
- entity resolution precision and recall
- anomaly detection rates
- governance workflow performance
- stewardship intervention frequency
Regular model retraining ensures that AI agents remain accurate as business rules and data patterns change.
Scaling Across Domains and Integration
Once a pilot domain succeeds, organizations can expand continuous MDM across additional entities.
Typical expansion order:
- Customer
- Supplier
- Product
- Location
- Asset or operational data
Modern architectures rely on:
- API first integration
- event driven pipelines
- cloud native microservices
These capabilities allow master data to be distributed across operational and analytical systems in real time.
The Role of Human Oversight in AI Driven MDM
AI automation must be paired with human governance. This approach is known as human in the loop data management.
Humans typically review decisions involving:
- sensitive personal data
- low confidence entity matches
- cross domain merges
- regulatory relevant attributes
Human oversight provides three key benefits:
- Trust
Users remain confident in automated decisions.
- Explainability
Stewards can understand how data decisions were made.
- Compliance
Organizations maintain accountability under regulatory frameworks.
Architecture of Agentic Data Management Platforms
Modern agentic data platforms combine three architectural layers.
Graph Native Data Layer
Graph models represent entities and relationships natively.
This makes it easier to resolve complex relationships such as:
customer → account → location → asset
Agentic AI Layer
Autonomous AI agents manage:
- schema mapping
- entity resolution
- data quality monitoring
- governance enforcement
Cloud Native Integration Layer
API first architecture enables integration with modern data ecosystems including:
- Microsoft Fabric
- Azure data services
- operational SaaS systems
- analytics platforms
Graph structures dramatically improve entity resolution and data lineage visibility.
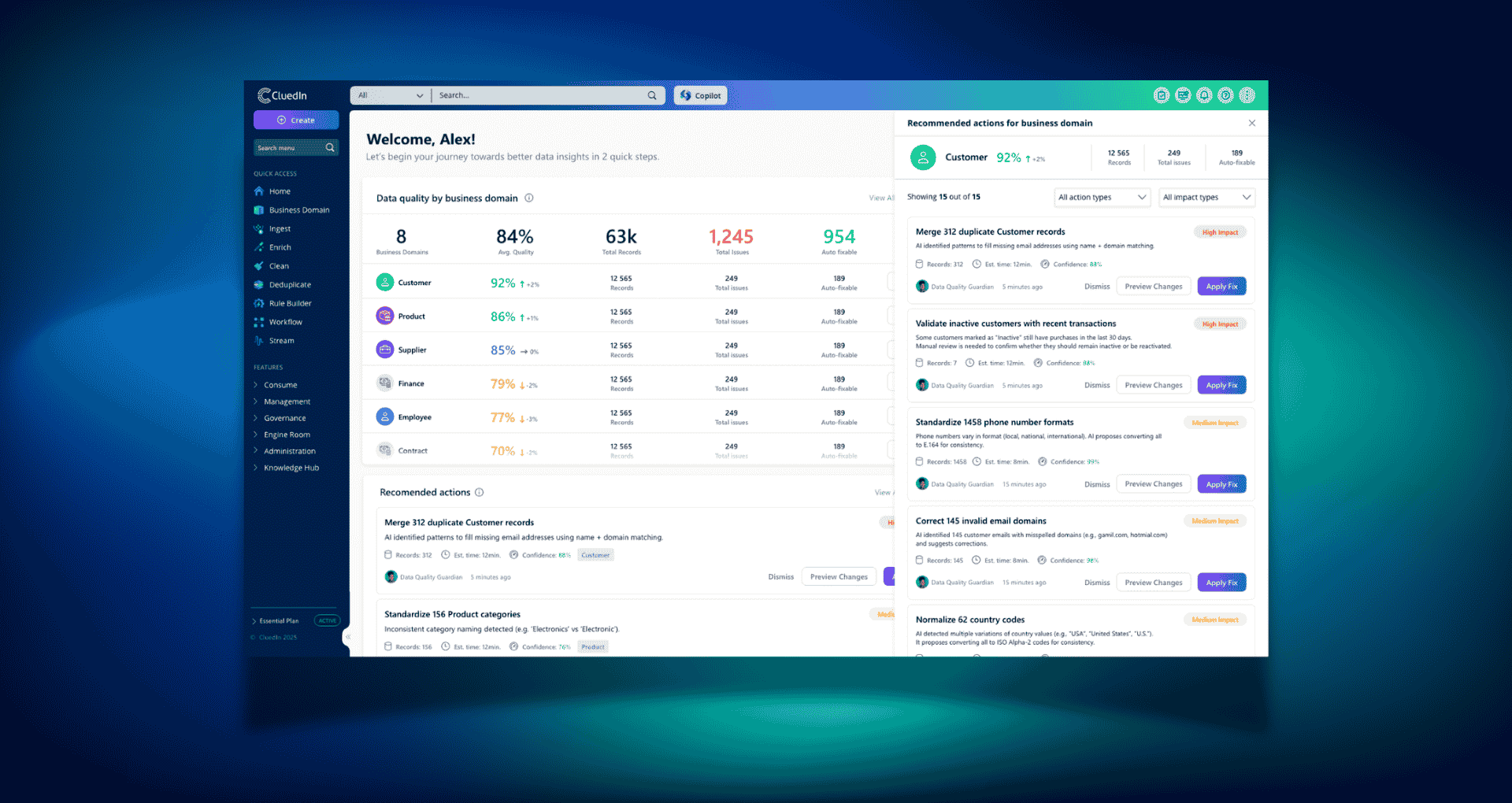
Image: Continuous Master Data Management
Platforms such as CluedIn combine these architectural layers to enable agentic Master Data Management without heavy manual modelling, allowing enterprises to onboard and govern data faster.
Real World Benefits of Continuous MDM with AI
Organizations adopting AI driven MDM commonly report measurable improvements.
| Outcome |
Impact |
| Faster data onboarding |
weeks instead of months |
| Automated entity resolution |
over 90 percent automation |
| Duplicate reduction |
significant reduction in data errors |
| Improved metadata quality |
greater data discoverability |
| Reduced governance workload |
stewards focus on high value decisions |
These improvements directly enable better analytics, AI readiness, and regulatory compliance.
The Future of Agentic Master Data Management in Europe
European enterprises face particularly strong pressures around data governance and sovereignty.
Regulations such as GDPR require:
- clear data lineage
- strict access controls
- auditable governance processes
Agentic data management platforms help address these challenges by combining automation with explainable governance.
Key Trends in Europe
- increasing demand for sovereign cloud architectures
- stronger regulatory scrutiny of data usage
- growth of AI driven operational systems
Continuous MDM allows organizations to maintain trusted master data while meeting these regulatory expectations.
Strategic Recommendations for Enterprises
Organizations evaluating agentic MDM should consider the following approach:
-
Start with a focused high value pilot domain
-
Establish governance and stewardship workflows early
-
Use AI to automate onboarding and entity resolution
-
Maintain human oversight for sensitive decisions
-
Monitor quality metrics continuously
-
Expand domain by domain across the enterprise
Enterprises that adopt continuous, AI driven MDM early will be better positioned to support advanced analytics, AI initiatives, and regulatory compliance.
The scale and complexity of modern enterprise data means traditional governance approaches are no longer sufficient. For more on this topic, download our most recent white paper, Data Has Outgrown Humans.
Platforms such as CluedIn enable organizations to implement agentic Master Data Management in modern cloud environments.
Frequently Asked Questions
What is continuous Master Data Management and why is it important?
Continuous Master Data Management uses AI driven automation to keep master data synchronized, accurate, and governed across enterprise systems at all times.
How do AI agents improve data quality?
AI agents automatically detect errors, identify duplicates, and suggest corrections while learning from human feedback to improve accuracy over time.
What role does human oversight play?
Human stewards review ambiguous or high risk decisions, ensuring compliance and maintaining trust in automated governance processes.
How do agentic data platforms differ from traditional MDM?
Agentic platforms use autonomous AI agents to continuously manage data, whereas traditional MDM relies heavily on static rules and manual processes.
What are best practices for implementing continuous MDM?
Start with a pilot domain, define measurable KPIs, automate onboarding and governance workflows, maintain human oversight, and scale gradually across domains.