Why Master Data Is the Hidden Key to ERP Success


AI adoption is surging across industries, but many initiatives still stumble. One often overlooked reason is poor data governance. Industry studies estimate up to 85% of AI projects fail, largely due to data quality issues and lack of trust in data. AI is only as smart as the data you feed it. That’s why data governance isn’t just an IT checkbox, it’s the foundation of successful AI.
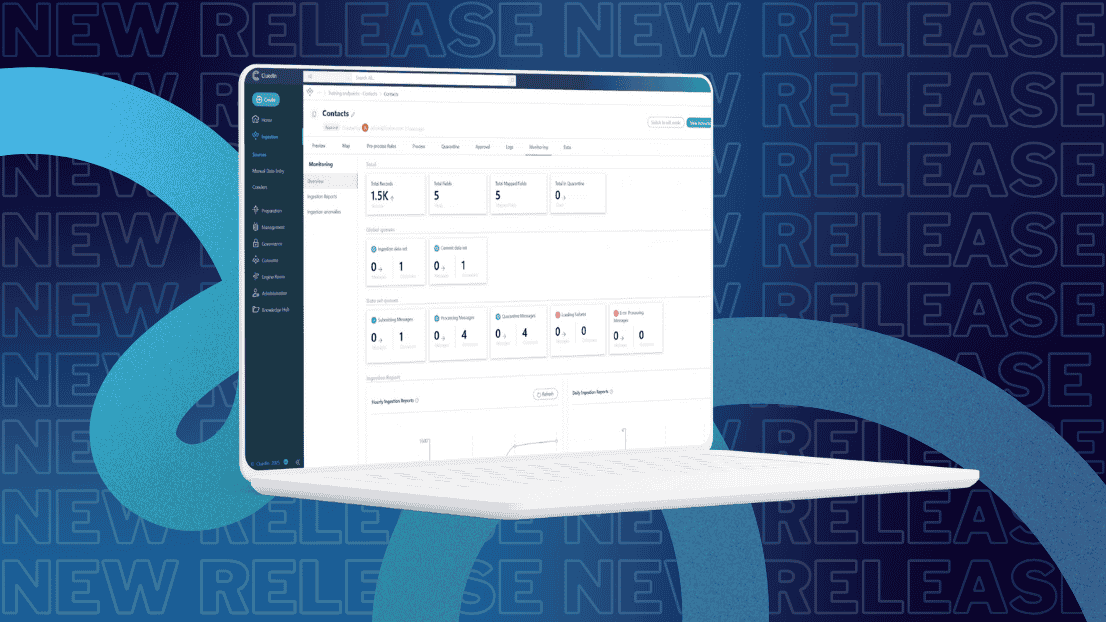
At CluedIn, we're committed to helping organizations master their data with speed, clarity, and confidence. With the release of CluedIn 2025.01, we’ve introduced a wave of powerful enhancements designed to simplify data onboarding, improve governance, and give users more control over how data is validated, approved, and used across the business.
Knowledge is power, and having near real-time intelligence about your customers, products, locations, and assets is essential for any organisation aiming to remain competitive and foster growth. This necessity is particularly pronounced during periods of economic uncertainty, such as pandemics and recessions, where businesses strive not only to manage costs but also to adapt and respond to change.
For instance, a manufacturing company with multiple locations, product lines, and suppliers could leverage insights into the total cost of production by product line, combined with regional customer buying preferences, to make informed decisions about product divestment or discontinuation.
Reflecting this trend, Gartner forecasts that worldwide IT spending will reach $5.61 trillion in 2025, marking a 9.8% increase from 2024. This growth is largely driven by investments in AI infrastructure, with spending on AI-optimized servers expected to surpass $202 billion, more than doubling expenditure on standard server hardware. Such investments underscore the critical role of technology — particularly analytics and business intelligence systems — as enablers of automation, enhanced digital experiences, and streamlined operations, all aimed at reducing costs and bolstering profitability.
Hang on a minute though!
Isn’t this exactly what many businesses have been trying to do for years?
Digital transformation is nothing new, and neither is the need to collect and analyse swathes of data in order to fuel that transformation. Organisations have already made significant investments in Data Lakes, Data Warehouses, Business Intelligence tools, and Analytics platforms – and the people who administer them. Yet still it seems like something is missing. Still it appears that technology and business leaders are searching for the insights they need and are prepared to pump in more investment in order to find it.
But is the answer really spending more money on more tools and data stewards, scientists, and engineers to deploy and manage them? Or is there a more fundamental, basic problem that needs addressing? We think there is. We believe that one of the major reasons enterprises are struggling is because they have a fundamental data quality issue, in that they have no way of managing data quality in a consistent and automated fashion. They have the data, and they have the tools to analyse it, but the data itself is siloed, inconsistent, stale, inaccurate… or all of the above. The output of analytics and business intelligence tools can only ever be as strong as the input – and if the data is poor, so the results will be too.
Surely there’s a way of taking poor quality data from different sources and bringing it together in a way that is consistent, accurate and scalable?
This has been the promise of Master Data Management (MDM) systems for the past 30 years, but in reality, the process still involves a great deal of time and effort from Data Engineers whose time would be better spent elsewhere. This is one of the reasons why 75% of MDM projects still fail, because instead of automatically fixing the majority of data quality issues and empowering business users to address the exceptions, human involvement from data and IT specialists is still required most of the time.
The problem is not that organisations have not invested enough in managing and analysing their data estate. The issue, until now, has been that the tools available to master that data have not been fit for purpose. Traditional MDM systems can only deliver a single view or Golden Record AFTER the modelling work has been done upfront – by you. Which typically takes months, requires heavy involvement from IT staff, and is out of date by the time it’s complete, thus fuelling the disconnect between MDM and business value.
Modern MDM platforms remove many of the barriers to creating value from data by automating or eliminating manual tasks and using advanced technologies like Graph, AI, and ML to ingest data from thousands of sources and allow the natural data model to emerge. This means leaving data in its natural state, and projecting it into your Information Models on demand. This also opens the door to having an MDM system that can host your data model in 15, 20, or 25 different shapes. They are also built for the Cloud, which means that they are easy to install, simple to set up and can scale up or down as you require. Perhaps most importantly, they break the traditional model of technology teams assuming sole responsibility for mastering data by giving business users access to the data and the power to run their own queries, to build their own information models, and interrogate data in their own ways.
In many ways, the new breed of MDM platform doesn’t look much like MDM at all. We believe that MDM as we know it will cease to exist, and we are entering a new category – that of Augmented Data Management – which seeks to simplify and speed up the process of preparing data for insights. It will still have many of the inner workings and expectations of MDM, but will capitalize on the influx of modern technology. With so much riding on the output of analytics and intelligence initiatives, it is crucial that a fully governed, reliable, compliant, and accurate supply of data is made available to the whole organisation.
So before building the case for increasing your investment in data and analytics, it is worth considering that it might not be more investment that is needed, but a change in focus. A solid data foundation – one that doesn’t discriminate between different types and sources of data – should always be the first priority when it comes to providing actionable intelligence and commercial insights to the business. Without it, analytics and BI tools will never deliver the outcomes demanded by organisations today.
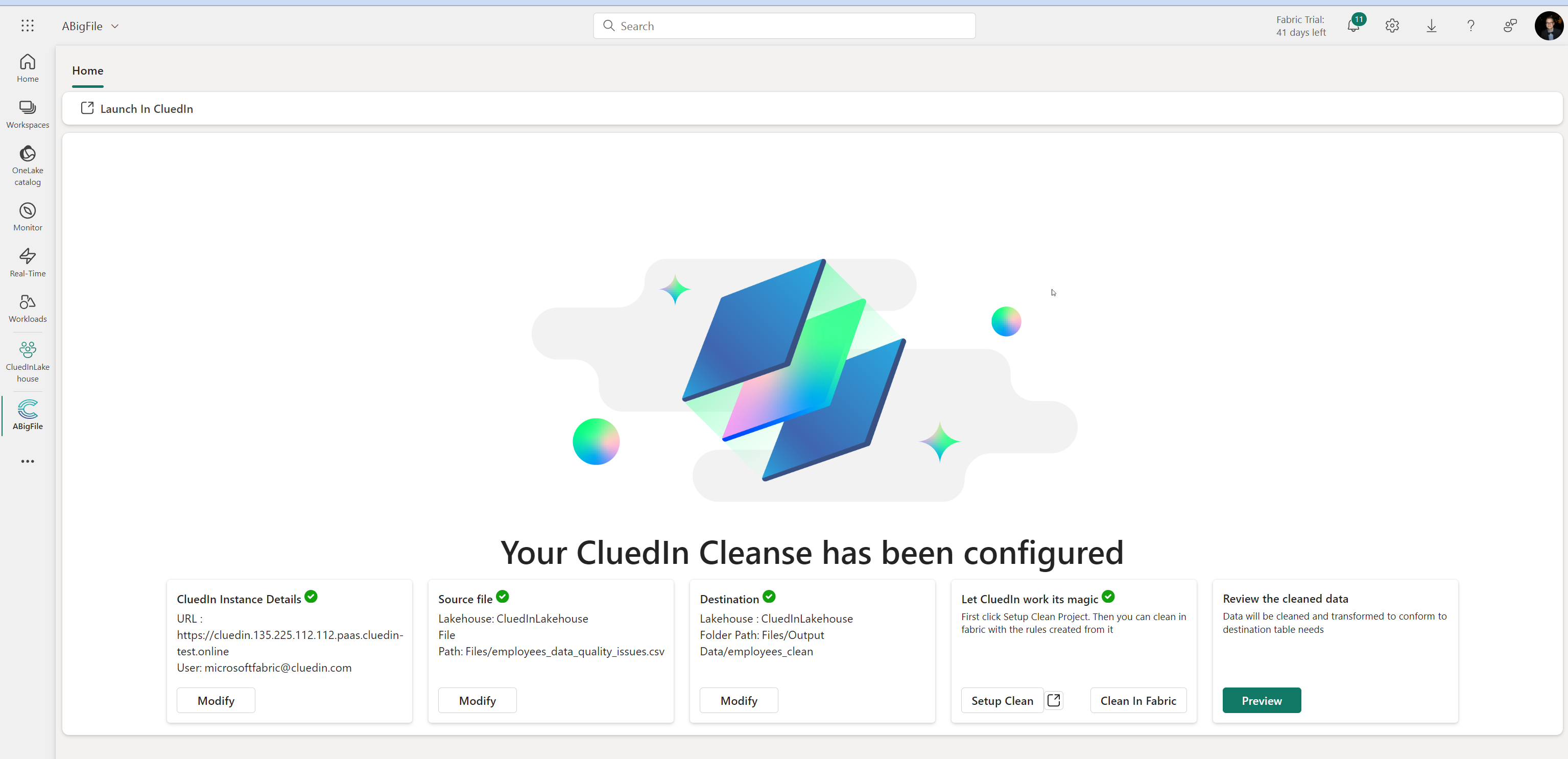
We're thrilled to announce the release of the CluedIn Microsoft Fabric Workload—a major step forward for the data management industry and a powerful new capability for Microsoft Fabric and CluedIn customers.

CluedIn, a leading provider of modern Master Data Management (MDM) and data quality solutions, today announced its integration with Open Mirroring in Microsoft Fabric. This development empowers enterprises to seamlessly synchronize, govern, and enrich their data across platforms, unlocking new levels of efficiency and insight in data management.

CluedIn, a leader in modern Master Data Management (MDM), proudly announces its integration into Microsoft Fabric as a Fabric Workload. This milestone enhances CluedIn’s position as a flexible and business-friendly data management platform, empowering organizations to seamlessly unify, enrich, and govern their data within the Microsoft ecosystem.

The ability to effectively manage and utilize data is more important than ever. Master Data Management (MDM) has become a cornerstone for organizations seeking to achieve a unified, accurate, and comprehensive view of their critical data assets. The recent Gartner Market Guide for Master Data Management Solutions 2024 provided valuable insights into the current trends and strategic recommendations that are shaping the future of Master Data Management.
As a prominent player in the MDM space, CluedIn is uniquely equipped to address these trends and deliver innovative solutions that drive business success.
Leveraging AI and Generative AI:
Reducing Deployment Time Frames:
Supporting Multiple Domains and Use Cases:
Enhancing ESG Reporting:
Driving Business Agility with Augmented MDM:
Ensuring Data Quality and Governance:
Facilitating Seamless Integration:
By focusing on these key areas, organizations can navigate the dynamic landscape of Master Data Management and unlock the full potential of their data. The insights and recommendations provided in the Gartner Market Guide serve as a valuable resource for businesses looking to adopt innovative solutions and drive strategic initiatives with confidence.

Master Data Management (MDM) and Data Quality (DQ) programs are at the heart of successful data-driven organizations. While many companies understand the importance of high-quality, trusted data, achieving this requires more than tools and technology—it demands a thoughtful approach to process, people, and progress.

We are excited to announce our first-ever virtual event, CluedInsight, set to take place on May 28, 2025. This dynamic, interactive event will provide data professionals with an exclusive opportunity to explore the future of data management, hear from thought leaders, and gain actionable insights that can transform their business operations.