From Excel to Excellence: Transforming Data Management with CluedIn
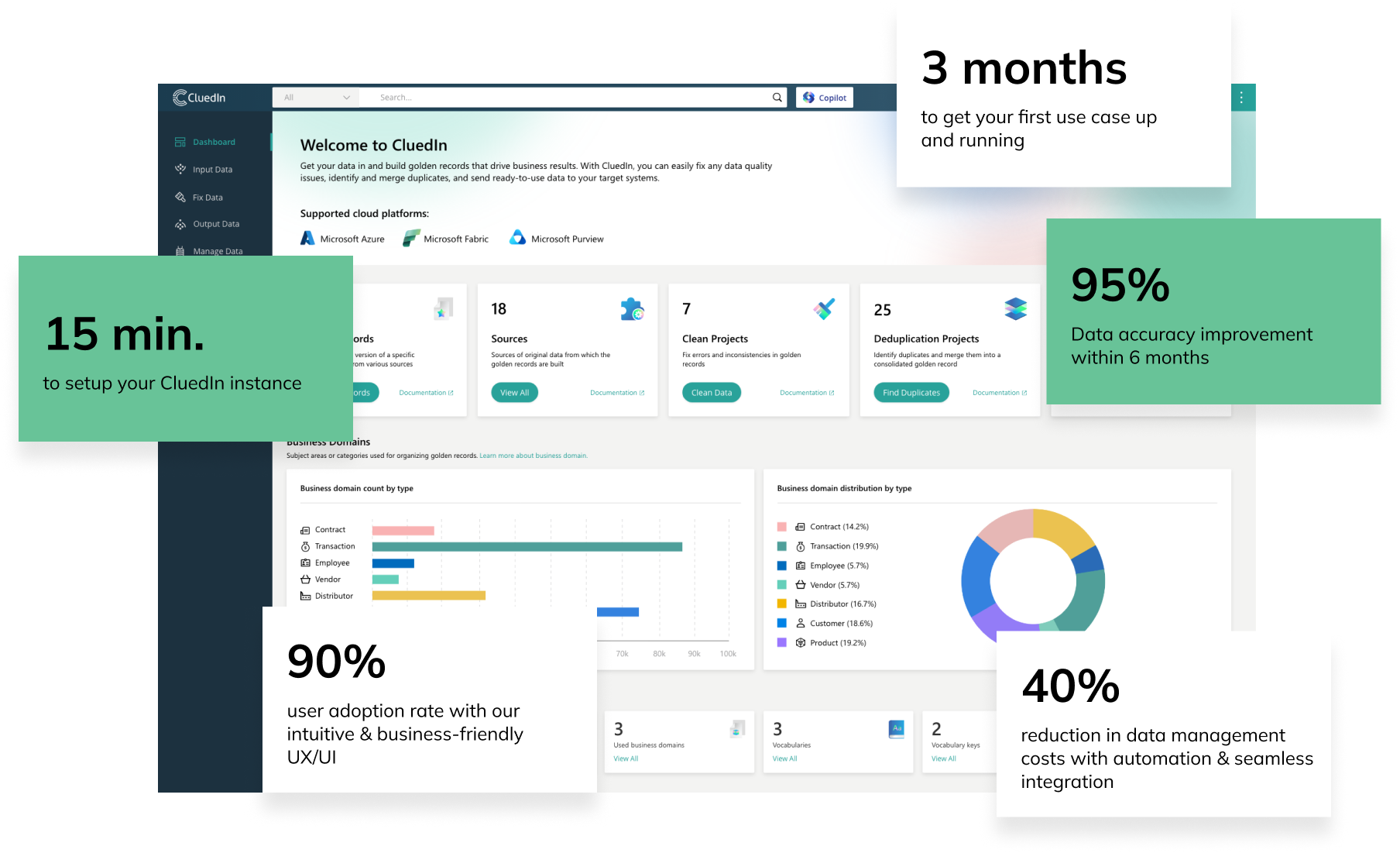
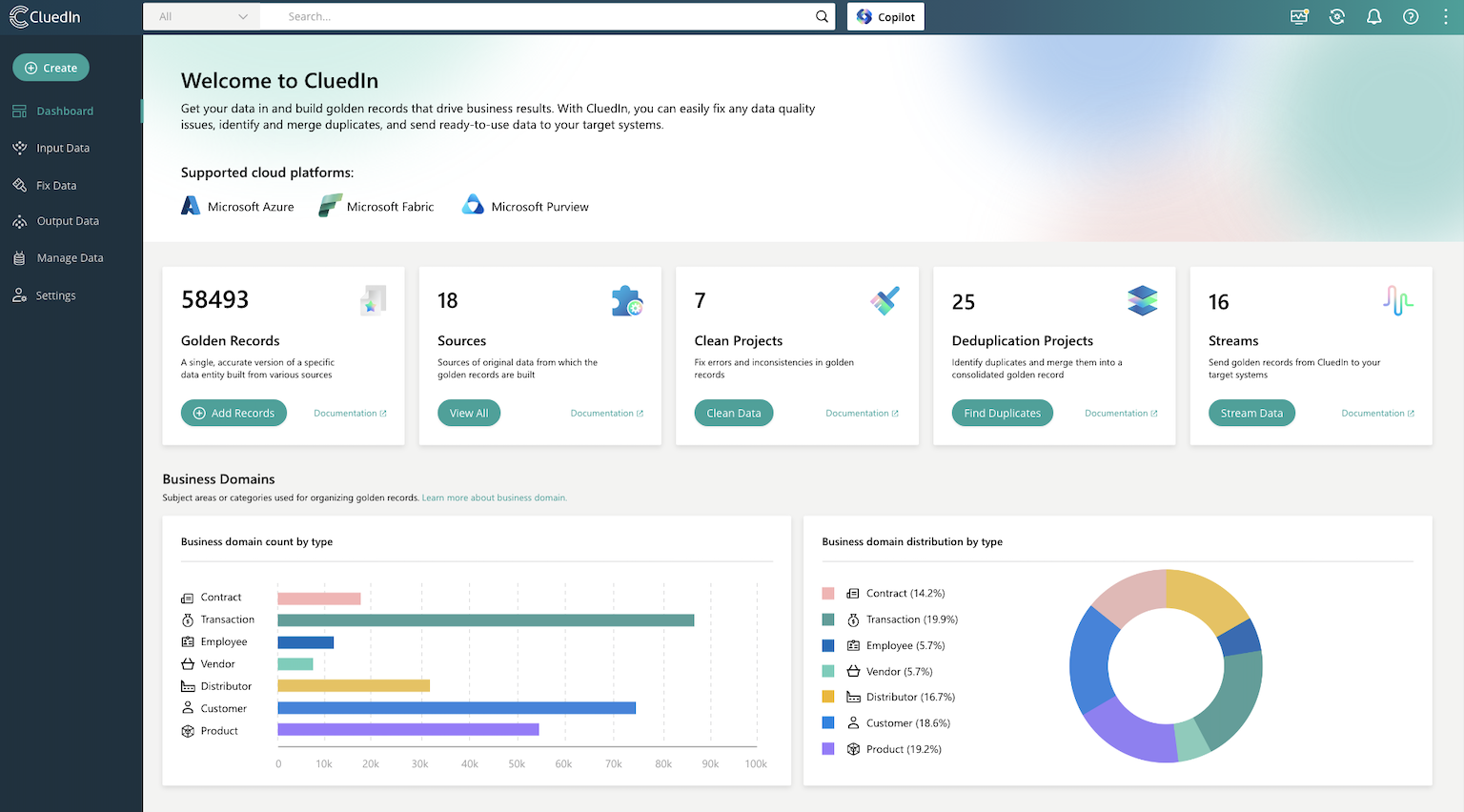
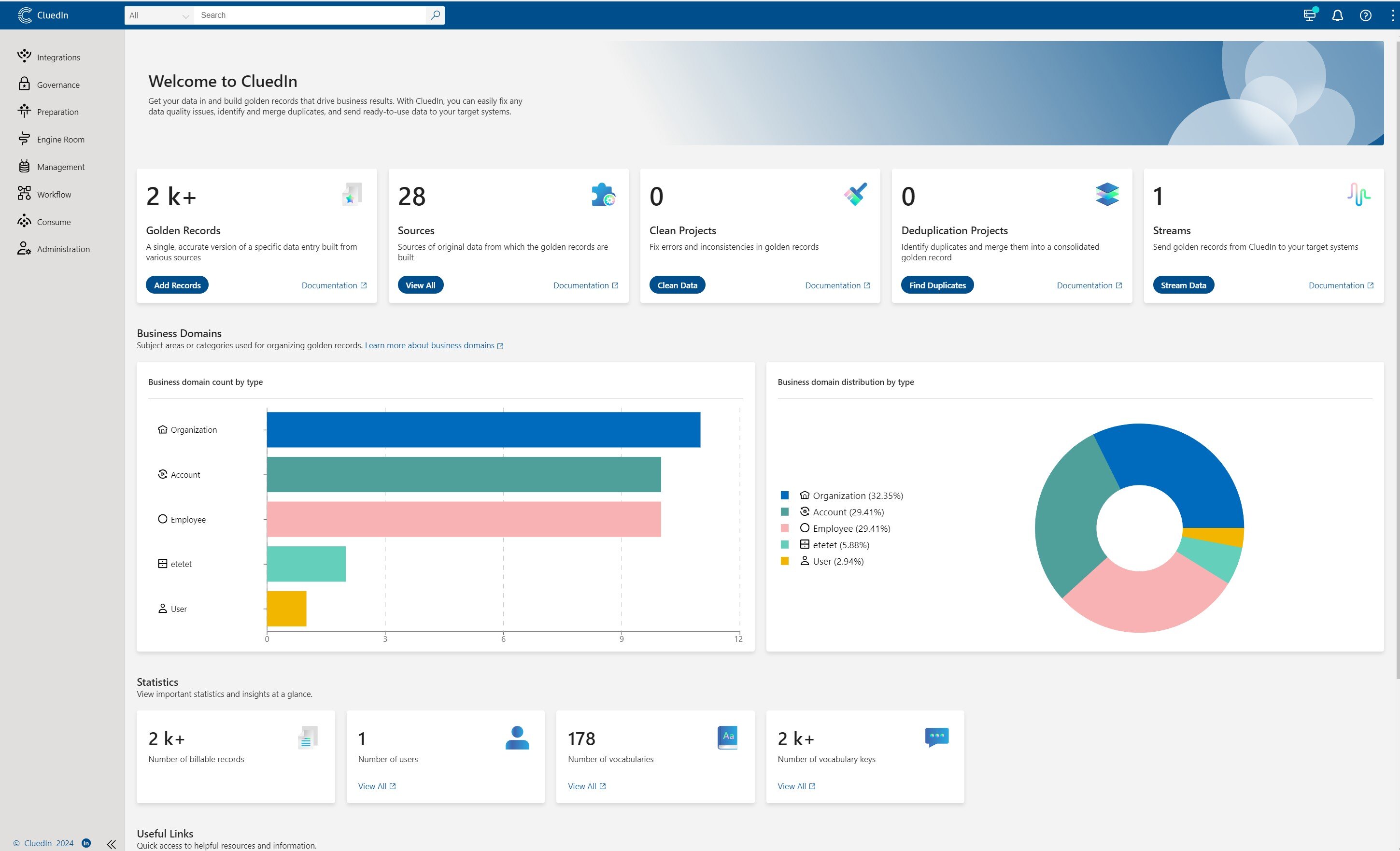
For decades, Excel has been the backbone of countless business operations. Its flexibility, accessibility, and familiarity have made it an indispensable tool in data management. However, as businesses grow and the complexity of data increases, Excel's limitations become apparent. It's time to move beyond operating your business on Excel and embrace a modern, centralized platform like CluedIn.