For years, the enterprise data industry has been trying to solve one big problem, access. Data was trapped in operational systems. Locked inside applications. Duplicated across regions. Rebuilt inside warehouses. Reconciled manually. Recreated for analytics. Recreated again for reporting. Then recreated again for AI, automation, compliance, and operational workflows.
So the industry did what it always does. It removed friction. We built cloud platforms. We built lakehouses. We built data fabrics. We built pipelines, connectors, semantic layers, sharing models, virtualization, and zero-copy architectures. We made it easier to bring data together, easier to query it, easier to expose it, and easier to use it without endlessly moving it from place to place.
And that progress is real. Microsoft Fabric and OneLake are a clear example of this direction. Microsoft describes OneLake shortcuts as a way to unify data across domains, clouds, and accounts, giving enterprises a single virtual data lake and reducing the need for edge copies, staging, and duplicated movement. Read Microsoft’s OneLake shortcuts documentation.
We solved movement. We didn't solve meaning
The industry has spent years making data easier to land, easier to connect, and easier to consume. But in many organisations, the harder work has been left behind: understanding what the data means, which version is right, which relationships matter, which records refer to the same entity, which systems should be trusted, and what should happen when those systems disagree. That is the uncomfortable truth behind the modern data platform.
And now, as enterprises pour more data into lakes, lakehouses, and platforms like OneLake, that gap is becoming impossible to ignore.
The modern data platform did not eliminate fragmentation. It centralised it.
The phrase “data lake” still carries a strange optimism. It suggests order. A single place. A shared resource. A foundation for analytics, AI, and operational intelligence.
But anyone who has worked inside a real enterprise data environment knows the reality is messier.
A familiar enterprise pattern:
- A customer record lands from Salesforce.
- Another version of the same customer exists in an ERP system.
- Invoicing data sits somewhere else.
- Support history lives in another platform.
- Consent status is held in a marketing system.
- Company hierarchy is maintained in a spreadsheet.
- Supplier information comes from a procurement tool.
- Product codes are different across regions.
Names are formatted differently. Addresses are inconsistent. Tax identifiers are incomplete. Relationships are implied, but not connected. Each system may be useful in isolation. Together, they do not automatically become truth.
This is the part that gets missed in a lot of modern data architecture narratives. Integration can make data visible, but visibility is not the same as alignment. A lake can bring data closer together physically or virtually, but it does not automatically tell you whether two records describe the same customer, which system has the most reliable value, whether the data is complete and accurate, whether everyone agrees what the data means, or whether the business can safely use it.
In data management terms, these are questions of identity, survivorship, quality, semantics, and trust. In business terms, they are the questions that determine whether data is actually usable.
-
The customer does not become accurate, complete, and trusted because the record is easier to query.
-
The supplier hierarchy does not become reliable because the tables are now accessible.
-
The invoice does not reconcile itself because the source is connected.
This is why the idea of a “data dump” matters. Not as a crude insult. As a precise description of what is now happening at enterprise scale.
Data is being made available faster than organisations can understand it. More sources. More schemas. More formats. More changes. More dependencies. More downstream use cases. More people consuming it. More AI systems waiting to act on it. The lake does not simply become bigger. It becomes more crowded, more conflicted, and harder to trust.
And the business still cannot answer the most basic question: can we trust what is in it?
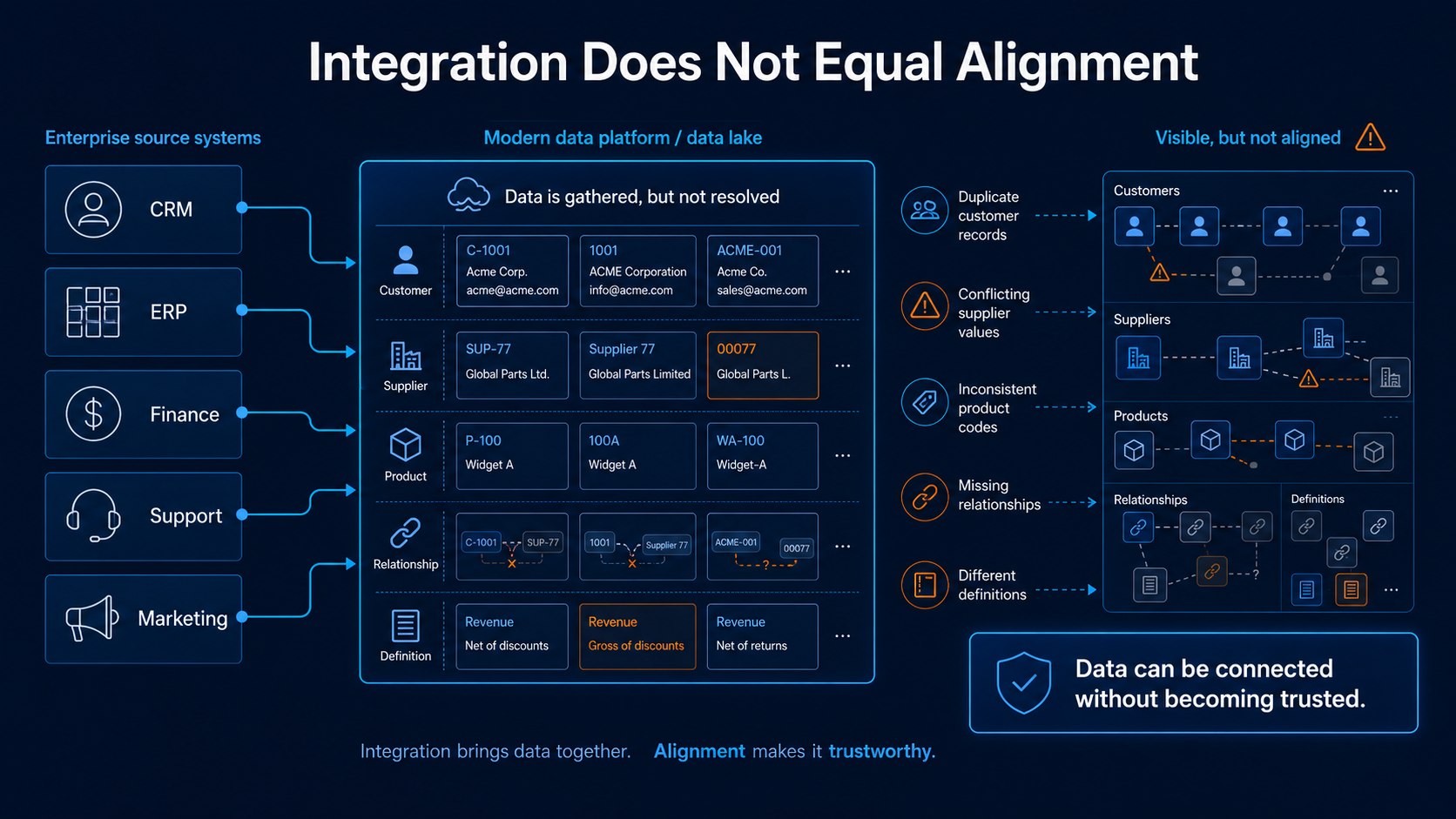
Image: Modern data platforms make enterprise data easier to access, but access alone does not resolve conflicting records, missing relationships, or inconsistent definitions.
Zero-copy integration changes the economics of access. It also changes the risk profile.
Zero-copy integration is one of the most important architectural shifts in enterprise data. It reduces duplication. It avoids unnecessary movement. It helps organisations query and use data where it already lives. It can reduce latency, simplify architecture, and accelerate access across tools and teams.
But every major efficiency gain also changes behaviour.
- When data becomes easier to connect, organisations connect more of it.
- When ingestion becomes simpler, ingestion accelerates.
- When access becomes less painful, more teams consume data earlier, faster, and with fewer checks.
That is not a criticism of zero-copy architectures. It is the reality of adoption.
The same thing happened with cloud storage. The cost of storage fell, so organisations stored more. The same happened with SaaS. The cost of deploying applications fell, so organisations deployed more applications. The same happened with BI. The cost of building dashboards fell, so organisations built more dashboards. Now it is happening to enterprise data access.
The easier it becomes to bring data into a unified analytical environment, the more exposed organisations become to the condition of that data. And that condition is often poor.
Research signals worth paying attention to
- Gartner says poor data quality remains one of the most frequently mentioned challenges preventing advanced analytics and AI deployment. Source
- Cloudera and Harvard Business Review Analytic Services found that only 7% of enterprises say their data is completely ready for AI, while 73% struggle with AI data preparation. Source
- Salesforce research says data and analytics leaders estimate more than a quarter of their organisational data is untrustworthy. Source
These are not small operational issues. They are symptoms of a bigger architectural problem. The modern data estate has become very good at access, but still weak at control. That is the tension every CDO, CIO, data architect, and AI leader now has to face.
The more data you make available, the more important it becomes to reconcile, standardise, and govern it. The more sources you connect, the more relationships matter. The more AI you deploy, the more trust matters.
And the faster the data changes, the less viable traditional control mechanisms become.
“If your data isn’t ready for generative AI, your business isn’t ready for generative AI.”
What do we mean by “mastering” data?
Mastering data means turning scattered, conflicting, incomplete records into trusted business entities that people and systems can rely on. It is how an organisation decides that two customer records are actually the same customer, which source should be trusted when values disagree, how missing information should be enriched, and how relationships between customers, products, suppliers, invoices, and locations should be maintained.
In traditional MDM language, this includes identity resolution, survivorship, data quality, semantics, governance, and trust. In plain terms, it is the work required to make data usable, believable, and safe for business decisions and AI.
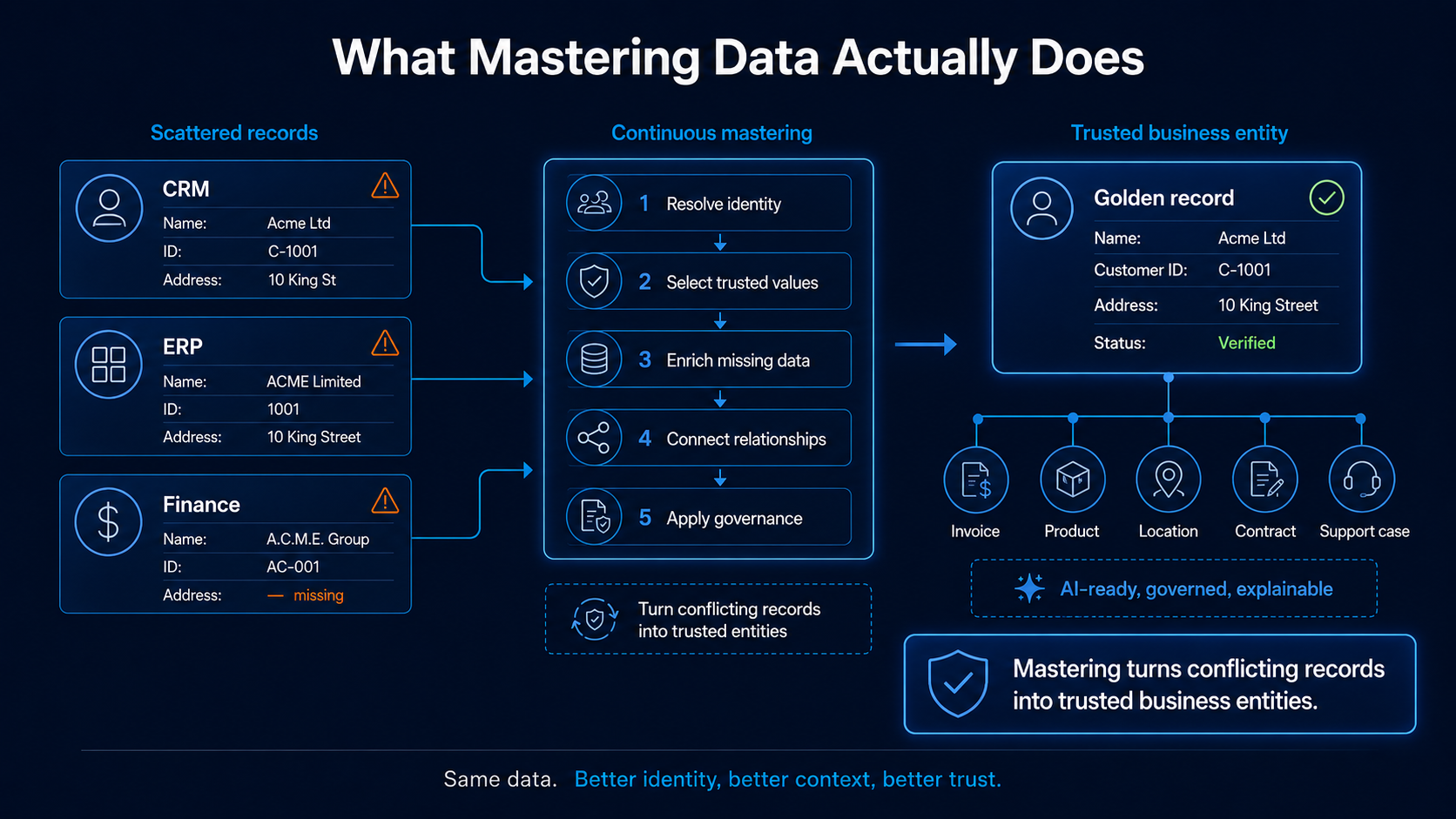
AI did not kill MDM. It exposed the version of MDM that was already failing.
“AI killed MDM” is a catchy line. It is also wrong. AI did not kill Master Data Management. If anything, AI has made the need for mastering more urgent than ever.
What AI has killed is the comfortable illusion that slow, static, human-heavy data management can keep up with the way modern enterprise data behaves.
Traditional MDM was designed around a different operating reality. One where sources were fewer, schemas were more stable, models could be defined upfront, workflows could be governed by human stewardship teams, and exceptions could be handled through queues, reviews, and periodic intervention. That model made sense when change was slower.
It makes much less sense when enterprise data is continuously flowing, continuously changing, and being consumed immediately by analytics, automation, and AI.
AI does not wait politely for stewardship teams to catch up. It consumes what is available. It reasons from the context it is given. It generates answers from the patterns it can see. If the customer is duplicated, the relationship is wrong, the consent flag is stale, the hierarchy is broken, or the product record is incomplete, AI does not necessarily know that the foundation is weak.
AI does not kill MDM. It kills the version of MDM built for a slower world.
Gartner predicts that through 2026, organisations will abandon 60% of AI projects unsupported by AI-ready data. Gartner also states that AI-ready data is not “one and done”, but a continuous practice requiring metadata, governance, observability, and ongoing improvement. Source
That is the important point. The need for trusted customer, product, supplier, financial, and operational data has not gone away. It has become more urgent. What has changed is the speed, scale, and operating model required to maintain that trust while data is constantly changing and AI is constantly consuming it.
The old question:
How do we create a trusted master record?
The new question:
How do we keep enterprise data trusted while it constantly changes, across systems that do not agree, for AI and analytics that cannot wait?
That is a very different problem. And it cannot be solved with a static rules engine, a six-month modelling project, and a growing queue of human tasks.
The real issue is not data quality.
It is control at scale.
Most organisations describe this as a data quality problem. That is too narrow. Data quality is part of it, but the deeper issue is control.
Control over:
- Identity
- Relationships
- Meaning
- Enrichment
- Lineage
- Survivorship
- Policy
- Business trust
This is where most enterprise data strategies start to show weakness. They have tools for storage. Tools for pipelines. Tools for cataloguing. Tools for governance. Tools for dashboards. Tools for AI. But the business problem does not sit neatly inside one of those boxes. The business problem is that data does not remain mastered simply because a platform exists.
It needs to be continuously resolved, continuously enriched, continuously checked, continuously governed, and continuously improved. And humans alone cannot do that at modern enterprise scale.
This is not about removing humans from data management. It is about admitting that human-only data management has reached its limit.
People should define policy. People should set thresholds. People should decide what level of autonomy is acceptable. People should review high-risk exceptions. People should own the business meaning of data.
But people should not spend their best hours chasing duplicate records, standardising formats, validating low-risk enrichment, manually linking obvious relationships, routing repetitive exceptions, or fixing the same class of issue thousands of times.
That is not stewardship. That is operational drag.
The next data platform battleground is not access. It is trust.
The first wave of modern data platforms was about scale. The second was about access. The third will be about trust. That does not mean trust as a vague brand promise. It means trust as an operational capability.
The questions that now matter:
- Can the platform understand that two records from different systems represent the same customer?
- Can it identify that a supplier relationship has changed?
- Can it detect that a field is complete but wrong?
- Can it preserve local context while maintaining a global view?
- Can it reconcile contradictory values using survivorship logic?
- Can it enrich missing attributes without breaking governance?
- Can it tell a human when confidence is low?
- Can it automatically act when confidence is high?
- Can it explain what changed, why it changed, who approved it, and what downstream systems were affected?
This is where the market is heading.
“You can have all of the fancy tools, but if your data quality is not good, you’re nowhere.”
That line should sting because it describes exactly where many enterprise AI strategies are today. The tools are impressive. The foundation is not.
Salesforce research says 89% of data and analytics leaders with AI in production have experienced inaccurate or misleading AI outputs. It also says 42% lack full confidence in the accuracy and relevance of AI outputs. Source
So the issue is not whether enterprises want AI. They do. The issue is whether their data estates are controlled enough for AI to be useful, safe, and trusted. And right now, the evidence says many are not.
The missing layer is not another dashboard. It is an operating model for continuous mastering.
This is the bridge many organisations miss. Mastering and control are not separate disciplines. Mastering is how data becomes trusted. Control is how it stays trusted when the environment around it keeps changing.
A customer record may be reconciled today, but a new source can arrive tomorrow. A supplier hierarchy may be accurate this month, but change after a merger, contract update, or regional system change. A product record may be complete in one application, but incomplete in another. In a slower data environment, mastering could be treated as a project or a periodic process. In a modern data estate, mastering has to become the ongoing mechanism of control.
Without continuous mastering, control is temporary. Without control, trust decays.
This is where the discussion needs to move beyond technology categories.
-
The answer is not more integration.
-
The answer is not more governance meetings.
-
The answer is not more dashboards showing poor quality.
-
The answer is not more people in stewardship queues.
Those things may help, but they do not change the operating model.
The operating model has to shift:
| From periodic correction | To continuous control |
| From static rules | To adaptive intelligence |
| From human-led fixing | To human-governed automation |
| From model-first implementation | To graph-native understanding |
| From isolated records | To entities, relationships, policies, context, and impact |
A customer is not just a row in a table. A customer is an entity connected to invoices, contracts, addresses, orders, consent, support interactions, legal entities, parent companies, risk profiles, regions, and products.
A supplier is not just a vendor ID. It is part of a hierarchy, a contract structure, a risk profile, a distribution network, and a set of operational dependencies.
A product is not just a SKU. It is connected to categories, attributes, suppliers, compliance rules, channels, regions, and customer experience.
Traditional data management often treats these as records to be cleaned.
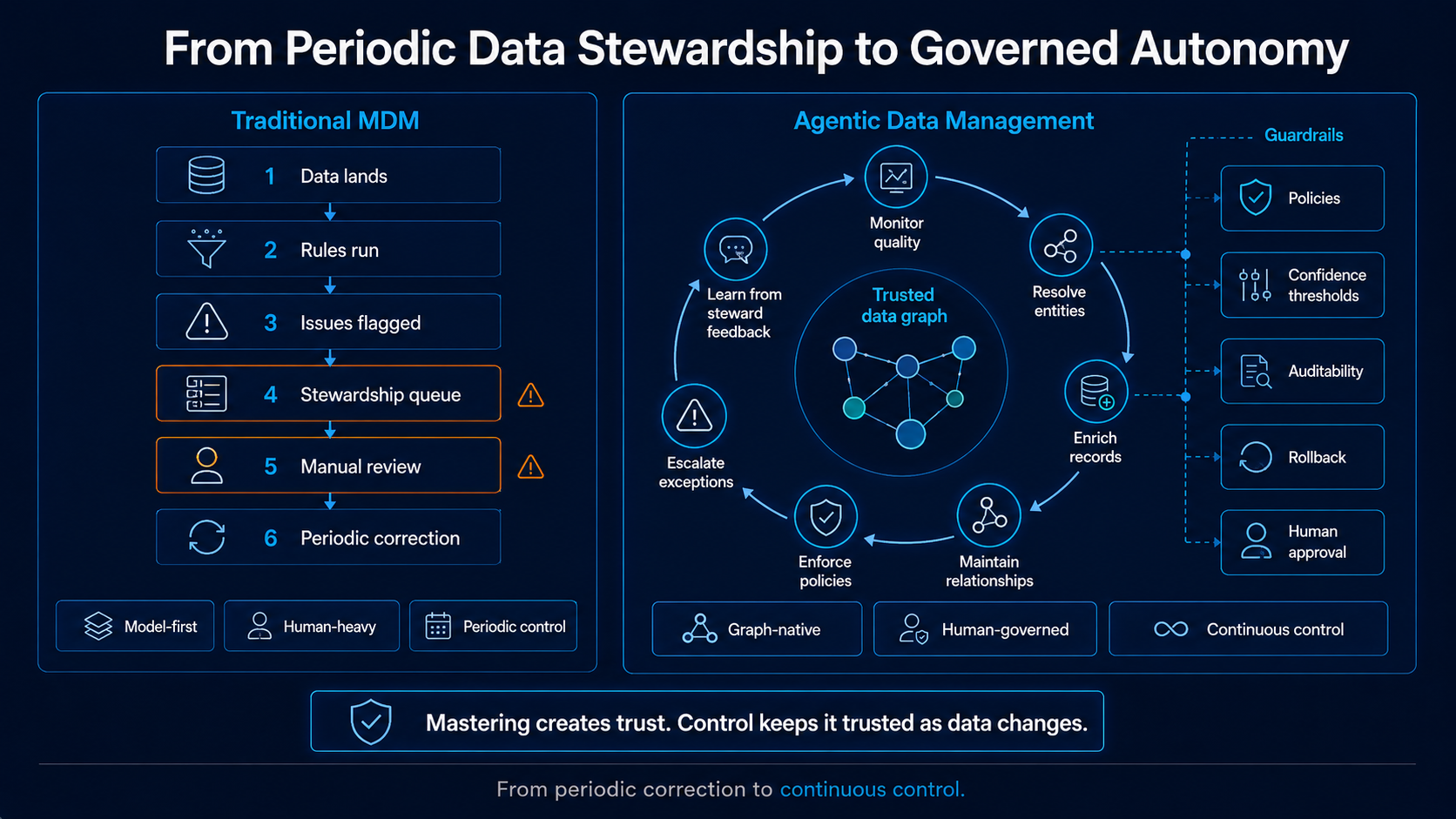
Image: Agentic Data Management shifts MDM from a periodic, human-heavy process to a governed system of continuous mastering and control.
Modern data management has to treat them as living business entities to be governed.
That is why graph-native thinking matters. A graph does not just store data. It captures relationships. It gives context. It allows the system to understand how a change in one place affects another. It gives agents the scaffolding they need to act with awareness rather than blindly executing isolated tasks.
At CluedIn, agents are graph-native, operating on a persistent model of enterprise entities and relationships, with memory, context, awareness of downstream impact, explainability, auditability, and rollback. We also position agentic MDM around continuous entity resolution, governance, enrichment, quality improvement, survivorship, relationship management, and trusted data delivery. Explore CluedIn’s Agentic Data Management platform.
That is not just a product feature story. It is a direct answer to the operating-model gap created by modern data platforms.
Agentic Data Management is not about replacing MDM. It is about making MDM viable again.
Master Data Management has never mattered more. But the old operating model cannot survive the modern data estate.
The core work still matters: identifying the same customer across systems, deciding which value should be trusted when systems disagree, maintaining reliable relationships, improving data quality, preserving lineage, and ensuring human oversight where judgement is required.
In MDM language, that means mastering, golden records, survivorship, governance, and stewardship. But the business outcome is simpler: trusted data that people, systems, and AI can safely use.
But the way these things are delivered has to change. Agentic Data Management is the shift from MDM as a project to MDM as an always-on system of control.
It means agents can:
- Monitor quality
- Detect anomalies
- Propose fixes
- Enrich records
- Identify duplicates
- Resolve entities
- Maintain relationships
- Route exceptions
- Enforce policies and learn from steward feedback
It means the system does not simply flag issues for humans to resolve later. It can act within defined guardrails. It means autonomy is not uncontrolled automation. It is policy-driven, explainable, reviewable, reversible action.
That distinction matters. The enterprise does not need agents that guess.
It needs agents that operate within trust boundaries.
At CluedIn make this distinction clearly, our agents are described as governed rather than guessing, with actions that can be traced, reviewed, or rolled back, and autonomy set per domain and action. Read more about CluedIn MDM.
Fabric, OneLake, and zero-copy architectures accelerate access. CluedIn provides the mastering and control layer that keeps the data usable.
The future of MDM is not more manual control, it is governed autonomy.
This is the shift modern enterprises now have to make. Fabric, OneLake, and zero-copy architectures accelerate access to data. But access alone does not make data usable, trusted, or ready for AI. To get there, enterprises need a continuous mastering and control layer that can keep pace with the speed of the modern data estate. That is the real evolution of MDM: not its death, but its reinvention for an AI-driven world.
The data dump is here. Organisations can keep filling the lake and hope trust appears later. Or they can master the data as it lands, as it changes, and as AI depends on it. Only one of those paths is fit for AI.
FINAL THOUGHT
The next generation of enterprise data management will not be defined by how much data it can ingest. It will be defined by how continuously it can understand, govern, improve, and activate that data.
Bring control to the modern data estate
CluedIn brings Agentic Data Management to the modern Microsoft data estate, continuously mastering, governing, enriching, and improving enterprise data where it already lives.